
Category: pro
Python hosting: Host, run, and code Python in the cloud!
Computer vision
Image histogram
A histogram is collected counts of data organized into a set of bins. Every bin shows the frequency. OpenCV can generate histograms for both color and gray scale images. You may want to use histograms for computer vision tasks.
Related course
Histogram example
Given an image we can generate a histogram for the blue, green and red values.
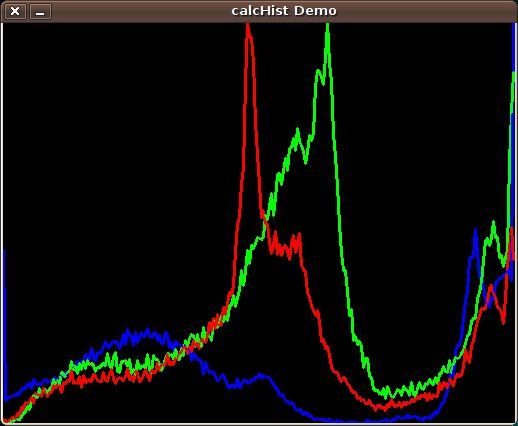
We use the function cv.CalcHist(image, channel, mask, histSize, range)
Parameters:
- image: should be in brackets, the source image of type uint8 or float32
- channel: the color channel to select. for grayscale use [0]. color image has blue, green and red channels
- mask: None if you want a histogram of the full image, otherwise a region.
- histSize: the number of bins
- range: color range:
Histogram for a color image:
# draw histogram in python. import cv2 import numpy as np img = cv2.imread('image.jpg') h = np.zeros((300,256,3)) bins = np.arange(256).reshape(256,1) color = [ (255,0,0),(0,255,0),(0,0,255) ] for ch, col in enumerate(color): hist_item = cv2.calcHist([img],[ch],None,[256],[0,255]) cv2.normalize(hist_item,hist_item,0,255,cv2.NORM_MINMAX) hist=np.int32(np.around(hist_item)) pts = np.column_stack((bins,hist)) cv2.polylines(h,[pts],False,col) h=np.flipud(h) cv2.imshow('colorhist',h) cv2.waitKey(0) |
Image data and operations
OpenCV (cv2) can be used to extract data from images and do operations on them. We demonstrate some examples of that below:
Related courses:
Image properties
We can extract the width, height and color depth using the code below:
import cv2 import numpy as np # read image into matrix. m = cv2.imread("python.png") # get image properties. h,w,bpp = np.shape(m) # print image properties. print "width: " + str(w) print "height: " + str(h) print "bpp: " + str(bpp) |
Access pixel data
We can access the pixel data of an image directly using the matrix, example:
import cv2 import numpy as np # read image into matrix. m = cv2.imread("python.png") # get image properties. h,w,bpp = np.shape(m) # print pixel value y = 1 x = 1 print m[y][x] |
To iterate over all pixels in the image you can use:
import cv2 import numpy as np # read image into matrix. m = cv2.imread("python.png") # get image properties. h,w,bpp = np.shape(m) # iterate over the entire image. for py in range(0,h): for px in range(0,w): print m[py][px] |
Image manipulation
You can modify the pixels and pixel channels (r,g,b) directly. In the example below we remove one color channel:
import cv2 import numpy as np # read image into matrix. m = cv2.imread("python.png") # get image properties. h,w,bpp = np.shape(m) # iterate over the entire image. for py in range(0,h): for px in range(0,w): m[py][px][0] = 0 # display image cv2.imshow('matrix', m) cv2.waitKey(0) |
To change the entire image, you’ll have to change all channels: m[py][px][0], m[py][px][1], m[py][px][2].
Save image
You can save a modified image to the disk using:
cv2.imwrite('filename.png',m) |
Object detection with templates
Template matching is a technique for finding areas of an image that are similar to a patch (template).
Its application may be robotics or manufacturing.
Related courses:
Master Computer Vision with OpenCV
Introduction
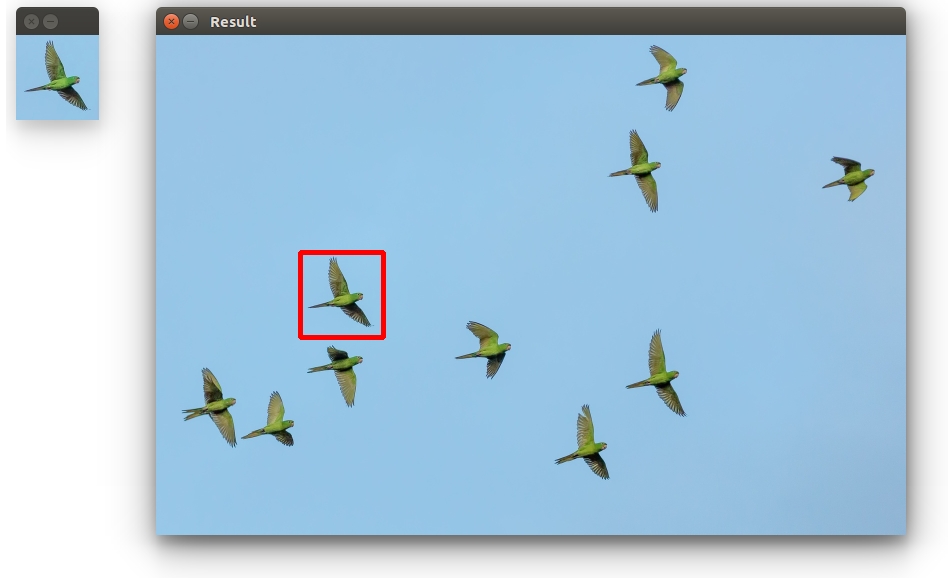
A patch is a small image with certain features. The goal of template matching is to find the patch/template in an image.
Download Computer Vision Examples and Course
To find them we need both:
- Source Image (S) : The space to find the matches in
- Template Image (T) : The template image
The template image T is slided over the source image S (moved over the source image), and the program tries to find matches using statistics.
Template matching example
Lets have a look at the code:
import numpy as np import cv2 image = cv2.imread('photo.jpg') template = cv2.imread('template.jpg') # resize images image = cv2.resize(image, (0,0), fx=0.5, fy=0.5) template = cv2.resize(template, (0,0), fx=0.5, fy=0.5) # Convert to grayscale imageGray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) templateGray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY) # Find template result = cv2.matchTemplate(imageGray,templateGray, cv2.TM_CCOEFF) min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) top_left = max_loc h,w = templateGray.shape bottom_right = (top_left[0] + w, top_left[1] + h) cv2.rectangle(image,top_left, bottom_right,(0,0,255),4) # Show result cv2.imshow("Template", template) cv2.imshow("Result", image) cv2.moveWindow("Template", 10, 50); cv2.moveWindow("Result", 150, 50); cv2.waitKey(0) |
Explanation
First we load both the source image and template image with imread(). We resize themand convert them to grayscale for faster detection:
image = cv2.imread('photo.jpg') template = cv2.imread('template.jpg') image = cv2.resize(image, (0,0), fx=0.5, fy=0.5) template = cv2.resize(template, (0,0), fx=0.5, fy=0.5) imageGray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) templateGray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY) |
We use the cv2.matchTemplate(image,template,method) method to find the most similar area in the image. The third argument is the statistical method.

This method has six matching methods: CV_TM_SQDIFF, CV_TM_SQDIFF_NORMED, CV_TM_CCORR, CV_TM_CCORR_NORMED, CV_TM_CCOEFF and CV_TM_CCOEFF_NORMED.
which are simply different statistical comparison methods
Finally, we get the rectangle variables and display the image.
Limitations
Template matching is not scale invariant nor is it rotation invariant. It is a very basic and straightforward method where we find the most correlating area. Thus, this method of object detection depends on the kind of application you want to build. For non scale and rotation changing input, this method works great.
You may like: Robotics or Car tracking with cascades.
Face detection in Google Hangouts video
In this tutorial you will learn how to apply face detection with Python. As input video we will use a Google Hangouts video. There are tons of Google Hangouts videos around the web and in these videos the face is usually large enough for the software to detect the faces.
Detection of faces is achieved using the OpenCV (Open Computer Vision) library. The most common face detection method is to extract cascades. This technique is known to work well with face detection. You need to have the cascade files (included in OpenCV) in the same directory as your program.
Related course
Master Computer Vision with OpenCV
Video with Python OpenCV
To analyse the input video we extract each frame. Each frame is shown for a brief period of time. Start with this basic program:
#! /usr/bin/python import cv2 vc = cv2.VideoCapture('video.mp4') c=1 fps = 24 if vc.isOpened(): rval , frame = vc.read() else: rval = False while rval: rval, frame = vc.read() cv2.imshow("Result",frame) cv2.waitKey(1000 / fps); vc.release() |
Upon execution you will see the video played without sound. (OpenCV does not support sound). Inside the while loop we have every video frame inside the variable frame.
Face detection with OpenCV
We will display a rectangle on top of the face. To avoid flickering of the rectangle, we will show it at it latest known position if the face is not detected.
#! /usr/bin/python import cv2 face_cascade = cv2.CascadeClassifier('lbpcascade_frontalface.xml') vc = cv2.VideoCapture('video.mp4') if vc.isOpened(): rval , frame = vc.read() else: rval = False roi = [0,0,0,0] while rval: rval, frame = vc.read() # resize frame for speed. frame = cv2.resize(frame, (300,200)) # face detection. faces = face_cascade.detectMultiScale(frame, 1.8, 2) nfaces = 0 for (x,y,w,h) in faces: cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),2) nfaces = nfaces + 1 roi = [x,y,w,h] # undetected face, show old on position. if nfaces == 0: cv2.rectangle(frame,(roi[0],roi[1]),(roi[0]+roi[2],roi[1]+roi[3]),(0,0,255),2) # show result cv2.imshow("Result",frame) cv2.waitKey(1); vc.release() |
In this program we simply assumed there is one face in the video screen. We reduced the size of the screen to speed up the processing time. This is fine in most cases because detection will work fine in lower resolutions. If you want to execute the face detection in “real time”, keeping the computational cycle short is mandatory. An alternative to this implementation is to process first and display later.
A limitation of this technique is that it does not always detect faces and faces that are very small or occluded may not be detected. It may show false positives such as a bag detected as face. This technique works quite well on certain type of input videos.
Car tracking with cascades
In this tutorial we will look at vehicle tracking using haar features. We have a haar cascade file trained on cars.
The program will detect regions of interest, classify them as cars and show rectangles around them.
Related courses:
Detecting with cascades
Lets start with the basic cascade detection program:
#! /usr/bin/python import cv2 face_cascade = cv2.CascadeClassifier('cars.xml') vc = cv2.VideoCapture('road.avi') if vc.isOpened(): rval , frame = vc.read() else: rval = False while rval: rval, frame = vc.read() # car detection. cars = face_cascade.detectMultiScale(frame, 1.1, 2) ncars = 0 for (x,y,w,h) in cars: cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),2) ncars = ncars + 1 # show result cv2.imshow("Result",frame) cv2.waitKey(1); vc.release() |
This will detect cars in the screen but also noise and the screen will be jittering sometimes. To avoid all of these, we have to improve our car tracking algorithm. We decided to come up with a simple solution.
Car tracking algorithm
For every frame:
- Detect potential regions of interest
- Filter detected regions based on vertical,horizontal similarity
- If its a new region, add to the collection
- Clear collection every 30 frames
Removing false positives
The mean square error function is used to remove false positives. We compare vertical and horizontal sides of the images. If the difference is to large or to small it cannot be a car.
ROI detection
A car may not be detected in every frame. If a new car is detected, its added to the collection.
We keep this collection for 30 frames, then clear it.
#! /usr/bin/python import cv2 import numpy as np def diffUpDown(img): # compare top and bottom size of the image # 1. cut image in two # 2. flip the top side # 3. resize to same size # 4. compare difference height, width, depth = img.shape half = height/2 top = img[0:half, 0:width] bottom = img[half:half+half, 0:width] top = cv2.flip(top,1) bottom = cv2.resize(bottom, (32, 64)) top = cv2.resize(top, (32, 64)) return ( mse(top,bottom) ) def diffLeftRight(img): # compare left and right size of the image # 1. cut image in two # 2. flip the right side # 3. resize to same size # 4. compare difference height, width, depth = img.shape half = width/2 left = img[0:height, 0:half] right = img[0:height, half:half + half-1] right = cv2.flip(right,1) left = cv2.resize(left, (32, 64)) right = cv2.resize(right, (32, 64)) return ( mse(left,right) ) def mse(imageA, imageB): err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2) err /= float(imageA.shape[0] * imageA.shape[1]) return err def isNewRoi(rx,ry,rw,rh,rectangles): for r in rectangles: if abs(r[0] - rx) < 40 and abs(r[1] - ry) < 40: return False return True def detectRegionsOfInterest(frame, cascade): scaleDown = 2 frameHeight, frameWidth, fdepth = frame.shape # Resize frame = cv2.resize(frame, (frameWidth/scaleDown, frameHeight/scaleDown)) frameHeight, frameWidth, fdepth = frame.shape # haar detection. cars = cascade.detectMultiScale(frame, 1.2, 1) newRegions = [] minY = int(frameHeight*0.3) # iterate regions of interest for (x,y,w,h) in cars: roi = [x,y,w,h] roiImage = frame[y:y+h, x:x+w] carWidth = roiImage.shape[0] if y > minY: diffX = diffLeftRight(roiImage) diffY = round(diffUpDown(roiImage)) if diffX > 1600 and diffX < 3000 and diffY > 12000: rx,ry,rw,rh = roi newRegions.append( [rx*scaleDown,ry*scaleDown,rw*scaleDown,rh*scaleDown] ) return newRegions def detectCars(filename): rectangles = [] cascade = cv2.CascadeClassifier('cars.xml') vc = cv2.VideoCapture(filename) if vc.isOpened(): rval , frame = vc.read() else: rval = False roi = [0,0,0,0] frameCount = 0 while rval: rval, frame = vc.read() frameHeight, frameWidth, fdepth = frame.shape newRegions = detectRegionsOfInterest(frame, cascade) for region in newRegions: if isNewRoi(region[0],region[1],region[2],region[3],rectangles): rectangles.append(region) for r in rectangles: cv2.rectangle(frame,(r[0],r[1]),(r[0]+r[2],r[1]+r[3]),(0,0,255),3) frameCount = frameCount + 1 if frameCount > 30: frameCount = 0 rectangles = [] # show result cv2.imshow("Result",frame) cv2.waitKey(1); vc.release() detectCars('road.avi') |
Final notes
The cascades are not rotation invariant, scale and translation invariant. In addition, Detecting vehicles with haar cascades may work reasonably well, but there is gain with other algorithms (salient points).
You may like: