
Category: database
csv to array python
dbms in python
In this tutorial you will learn how to use the SQLite database management system with Python. You will learn how to use SQLite, SQL queries, RDBMS and more of this cool stuff!
Related course: Master SQL Databases with PythonPyton Database
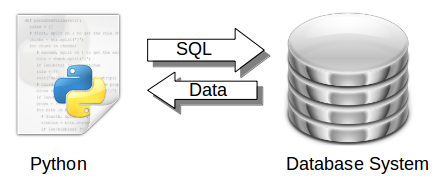
Data is retrieved from a database system using the SQL language.
Python has bindings for many database systems including MySQL, Postregsql, Oracle, Microsoft SQL Server and Maria DB.
One of these database management systems (DBMS) is called SQLite. SQLite was created in the year 2000 and is one of the many management systems in the database zoo.
SQL is a special-purpose programming language designed for managing data held in a databases. The language has been around since 1986 and is worth learning. The is an old funny video about SQL
SQLite

It is a self-contained, serverless, zero-configuration, transactional SQL database engine. The SQLite project is sponsored by Bloomberg and Mozilla.
Install SQLite:
Use this command to install SQLite:$ sudo apt-get install sqlite |
Verify if it is correctly installed. Copy this program and save it as test1.py
#!/usr/bin/python |
Execute with:
$ python test1.py |
It should output:
SQLite version: 3.8.2 |
What did the script above do?
The script connected to a new database called test.db with this line:
con = lite.connect('test.db') |
It then queries the database management system with the command
SELECT SQLITE_VERSION() |
which in turn returned its version number. That line is known as an SQL query.
Related course: Master SQL Databases with Python
SQL Create and Insert
The script below will store data into a new database called user.db
#!/usr/bin/python |
SQLite is a database management system that uses tables. These tables can have relations with other tables: it’s called relational database management system or RDBMS. The table defines the structure of the data and can hold the data. A database can hold many different tables. The table gets created using the command:
cur.execute("CREATE TABLE Users(Id INT, Name TEXT)") |
We add records into the table with these commands:
cur.execute("INSERT INTO Users VALUES(2,'Sonya')") |
The first value is the ID. The second value is the name. Once we run the script the data gets inserted into the database table Users:
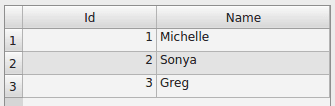
SQLite query data
We can explore the database using two methods: the command line and a graphical interface.
From console: To explore using the command line type these commands:
sqlite3 user.db |
This will output the data in the table Users.
sqlite> SELECT * FROM Users; |
From GUI: If you want to use a GUI instead, there is a lot of choice. Personally I picked sqllite-man but there are many others. We install using:
sudo apt-get install sqliteman |
We start the application sqliteman. A gui pops up.
Press File > Open > user.db. It appears like not much has changed, do not worry, this is just the user interface. On the left is a small tree view, press Tables > users. The full table including all records will be showing now.
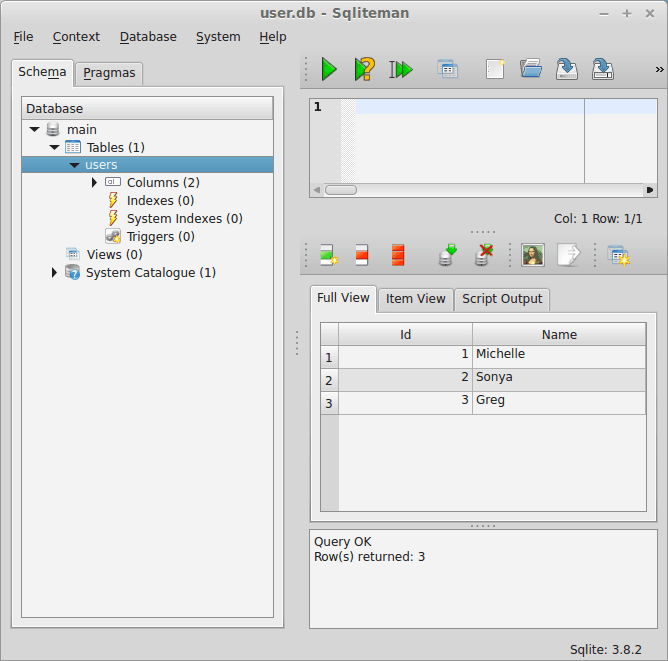
This GUI can be used to modify the records (data) in the table and to add new tables.
Related course: Master SQL Databases with PythonThe SQL database query language
SQL has many commands to interact with the database. You can try the commands below from the command line or from the GUI:
sqlite3 user.db |
We can use those queries in a Python program:
#!/usr/bin/python |
This will output all data in the Users table from the database:
$ python get.py |
Creating a user information database
We can structure our data across multiple tables. This keeps our data structured, fast and organized. If we would have a single table to store everything, we would quickly have a big chaotic mess. What we will do is create multiple tables and use them in a combination. We create two tables:
Users:

Jobs:

To create these tables, you can do that by hand in the GUI or use the script below:
# -*- coding: utf-8 -*- |
The jobs table has an extra parameter, Uid. We use that to connect the two tables in an SQL query:
SELECT users.name, jobs.profession FROM jobs INNER JOIN users ON users.ID = jobs.uid |
You can incorporate that SQL query in a Python script:
#!/usr/bin/python |
It should output:
$ python get2.py |
You may like: Databases and data analysis
python mysql
python postgresql
sqlalchemy orm
An object relational mapper maps a relational database system to objects. If you are unfamiliar with object orientated programming, read this tutorial first. The ORM is independent of which relational database system is used. From within Python, you can talk to objects and the ORM will map it to the database. In this article you will learn to use the SqlAlchemy ORM.
What an ORM does is shown in an illustration below:

Related course:
Creating a class to feed the ORM
We create the file tabledef.py. In this file we will define a class Student. An abstract visualization of the class below:

Observe we do not define any methods, only variables of the class. This is because we will map this class to the database and thus won’t need any methods.
This is the contents of tabledef.py:
from sqlalchemy import * |
Execute with:
python tabledef.py |
The ORM created the database file tabledef.py. It will output the SQL query to the screen, in our case it showed:
CREATE TABLE student ( |
Thus, while we defined a class, the ORM created the database table for us. This table is still empty.
Inserting data into the database
The database table is still empty. We can insert data into the database using Python objects. Because we use the SqlAlchemy ORM we do not have to write a single SQL query. We now simply create Python objects that we feed to the ORM. Save the code below as dummy.py
import datetime |
Execute with:
python dummy.py |
The ORM will map the Python objects to a relational database. This means you do not have any direct interaction from your application, you simply interact with objects. If you open the database with SQLiteman or an SQLite database application you’ll find the table has been created:

Query the data
We can query all items of the table using the code below. Note that Python will see every record as a unique object as defined by the Students class. Save the code as demo.py
import datetime |
On execution you will see:
James Boogie |
To select a single object use the filter() method. A demonstration below:
import datetime |
Output:
Eric York |
Finally, if you do not want the ORM the output any of the SQL queries change the create_engine statement to:
engine = create_engine('sqlite:///student.db', echo=False) |