
Python Sentiment Analysis
Sentiment Analysis
In Natural Language Processing there is a concept known as Sentiment Analysis.Given a movie review or a tweet, it can be automatically classified in categories.
These categories can be user defined (positive, negative) or whichever classes you want.
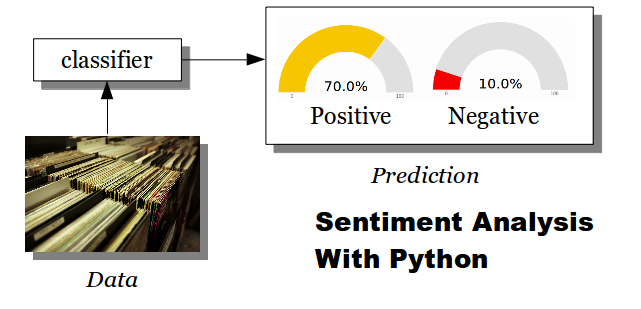 Sentiment Analysis, example flow
Sentiment Analysis, example flowRelated courses
Sentiment Analysis Example
Classification is done using several steps: training and prediction.The training phase needs to have training data, this is example data in which we define examples. The classifier will use the training data to make predictions.
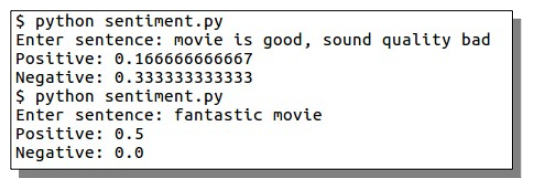 sentiment analysis, example runs
sentiment analysis, example runsWe start by defining 3 classes: positive, negative and neutral. Each of these is defined by a vocabulary:
positive_vocab = [ 'awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)' ]
negative_vocab = [ 'bad', 'terrible','useless', 'hate', ':(' ]
neutral_vocab = [ 'movie','the','sound','was','is','actors','did','know','words','not' ]Every word is converted into a feature using a simplified bag of words model:
def word_feats(words):
return dict([(word, True) for word in words])
positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab]
negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab]
neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab]
Our training set is then the sum of these three feature sets:
train_set = negative_features + positive_features + neutral_featuresWe train the classifier:
classifier = NaiveBayesClassifier.train(train_set)And make predictions.
Code example This example classifies sentences according to the training set.
import nltk.classify.util
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import names
def word_feats(words):
return dict([(word, True) for word in words])
positive_vocab = [ 'awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)' ]
negative_vocab = [ 'bad', 'terrible','useless', 'hate', ':(' ]
neutral_vocab = [ 'movie','the','sound','was','is','actors','did','know','words','not' ]
positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab]
negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab]
neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab]
train_set = negative_features + positive_features + neutral_features
classifier = NaiveBayesClassifier.train(train_set)
# Predict
neg = 0
pos = 0
sentence = "Awesome movie, I liked it"
sentence = sentence.lower()
words = sentence.split(' ')
for word in words:
classResult = classifier.classify( word_feats(word))
if classResult == 'neg':
neg = neg + 1
if classResult == 'pos':
pos = pos + 1
print('Positive: ' + str(float(pos)/len(words)))
print('Negative: ' + str(float(neg)/len(words)))
To enter the input sentence manually, use the input or raw_input functions. The better your training data is, the more accurate your predictions. In this example our training data is very small.
Training sets There are many training sets available:
A good dataset will increase the accuracy of your classifier.