
nltk stemming
Python hosting: Host, run, and code Python in the cloud!
A word stem represents the base or root form of a word, serving as a vital concept in the field of linguistics. In simpler terms, it is a method to normalize words.
For instance, the word “waiting” has the stem “wait.”
With the help of NLTK (Natural Language Toolkit), you can effortlessly identify word stems. This toolkit is particularly beneficial for text normalization processes.
Related course: Easy Natural Language Processing (NLP) in Python
Understanding Stemming in NLTK
To demonstrate stemming, let’s consider a set of related words:1
words = ["game","gaming","gamed","games"]
First, it’s crucial to import the required modules from NLTK:1
2from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
Using the above modules, you can stem the words in the provided list:1
2
3ps = PorterStemmer()
for word in words:
print(ps.stem(word))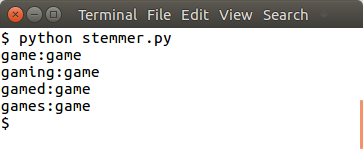
Stemming can also be extended to entire sentences. Here’s how:1
2
3
4sentence = "gaming, the gamers play games"
words = word_tokenize(sentence)
for word in words:
print(word + ":" + ps.stem(word))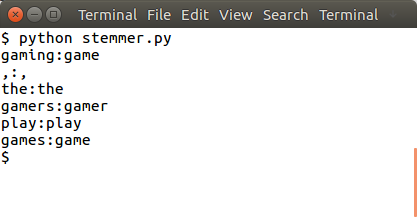
While several stemming algorithms exist, the Porter Stemmer (PorterStemmer) remains one of the most widely used and recognized.
Leave a Reply:
I tried with the word identifying i am getting as output identifi