
NLTK speech tagging
The module NLTK can automatically tag speech. Given a sentence or paragraph, it can label words such as verbs, nouns and so on.
NLTK - speech tagging example
The example below automatically tags words with a corresponding class.import nltk
from nltk.tokenize import PunktSentenceTokenizer
document = 'Whether you\'re new to programming or an experienced developer, it\'s easy to learn and use Python.'
sentences = nltk.sent_tokenize(document)
for sent in sentences:
print(nltk.pos_tag(nltk.word_tokenize(sent)))
This will output a tuple for each word:
 where the second element of the tuple is the class.
The meanings of these speech codes are shown in the table below:
where the second element of the tuple is the class.
The meanings of these speech codes are shown in the table below:

We can filter this data based on the type of word:
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
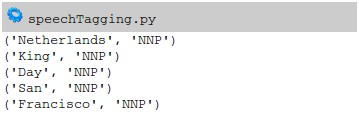
document = 'Today the Netherlands celebrates King\'s Day. To honor this tradition, the Dutch embassy in San Francisco invited me to'
sentences = nltk.sent_tokenize(document)
data = []
for sent in sentences:
data = data + nltk.pos_tag(nltk.word_tokenize(sent))
for word in data:
if 'NNP' in word[1]:
print(word)
which outputs:
 Speech tagging
Speech taggingThe classes include past tense, present. Using this technique we can quickly derive meaning from a text.