
NLTK - stemming
A word stem is part of a word. It is sort of a normalization idea, but linguistic. For example, the stem of the word waiting is wait.
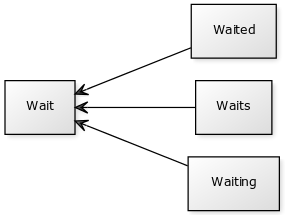 word stem
word stemRelated course
Practice Python with interactive exercises
NLTK - stemming Start by defining some words:
words = ["game","gaming","gamed","games"]We import the module:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenizeAnd stem the words in the list using:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
words = ["game","gaming","gamed","games"]
ps = PorterStemmer()
for word in words:
print(ps.stem(word))
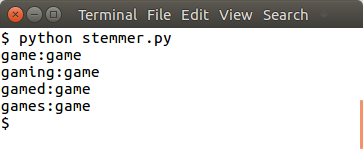 nltk word stem example
nltk word stem exampleYou can do word stemming for sentences too:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
ps = PorterStemmer()
sentence = "gaming, the gamers play games"
words = word_tokenize(sentence)
for word in words:
print(word + ":" + ps.stem(word))
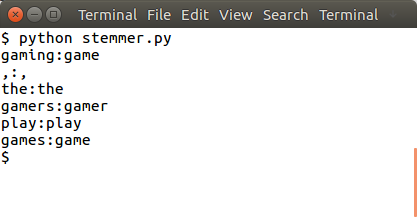 Stemming with NLTK
Stemming with NLTKThere are more stemming algorithms, but Porter (PorterStemer) is the most popular.