
Category: nltk
Python hosting: Host, run, and code Python in the cloud!
Tokenizing Words and Sentences with NLTK

In this article you will learn how to tokenize data (by words and sentences).
Related courseInstall NLTK
Install NLTK with Python 2.x using:
sudo pip install nltk |
Install NLTK with Python 3.x using:
sudo pip3 install nltk |
Installation is not complete after these commands. Open python and type:
import nltk nltk.download() |
A graphical interface will be presented:
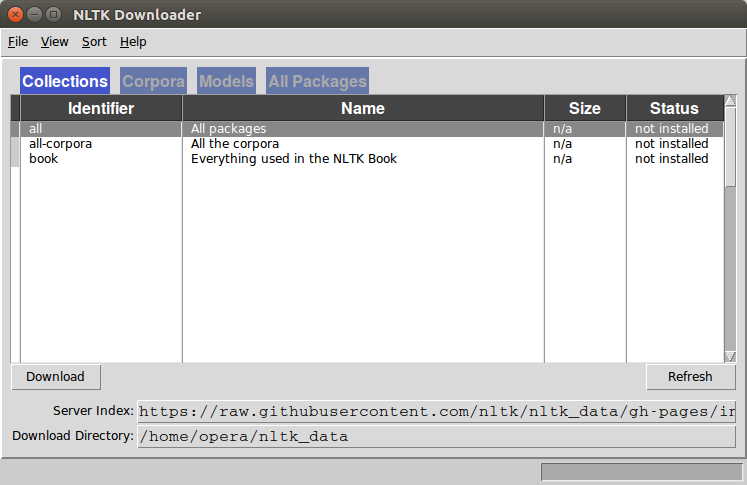
Click all and then click download. It will download all the required packages which may take a while, the bar on the bottom shows the progress.
Tokenize words
A sentence or data can be split into words using the method word_tokenize():
from nltk.tokenize import sent_tokenize, word_tokenize data = "All work and no play makes jack a dull boy, all work and no play" print(word_tokenize(data)) |
This will output:
['All', 'work', 'and', 'no', 'play', 'makes', 'jack', 'dull', 'boy', ',', 'all', 'work', 'and', 'no', 'play'] |
All of them are words except the comma. Special characters are treated as separate tokens.
Tokenizing sentences
The same principle can be applied to sentences. Simply change the to sent_tokenize()
We have added two sentences to the variable data:
from nltk.tokenize import sent_tokenize, word_tokenize data = "All work and no play makes jack dull boy. All work and no play makes jack a dull boy." print(sent_tokenize(data)) |
Outputs:
['All work and no play makes jack dull boy.', 'All work and no play makes jack a dull boy.'] |
NLTK and arrays
If you wish to you can store the words and sentences in arrays:
from nltk.tokenize import sent_tokenize, word_tokenize data = "All work and no play makes jack dull boy. All work and no play makes jack a dull boy." phrases = sent_tokenize(data) words = word_tokenize(data) print(phrases) print(words) |
NLTK stop words
Text may contain stop words like ‘the’, ‘is’, ‘are’. Stop words can be filtered from the text to be processed. There is no universal list of stop words in nlp research, however the nltk module contains a list of stop words.
In this article you will learn how to remove stop words with the nltk module.
Related courseNatural Language Processing: remove stop words
We start with the code from the previous tutorial, which tokenized words.
from nltk.tokenize import sent_tokenize, word_tokenize data = "All work and no play makes jack dull boy. All work and no play makes jack a dull boy." words = word_tokenize(data) print(words) |
We modify it to:
from nltk.tokenize import sent_tokenize, word_tokenize from nltk.corpus import stopwords data = "All work and no play makes jack dull boy. All work and no play makes jack a dull boy." stopWords = set(stopwords.words('english')) words = word_tokenize(data) wordsFiltered = [] for w in words: if w not in stopWords: wordsFiltered.append(w) print(wordsFiltered) |
A module has been imported:
from nltk.corpus import stopwords |
We get a set of English stop words using the line:
stopWords = set(stopwords.words('english')) |
The returned list stopWords contains 153 stop words on my computer.
You can view the length or contents of this array with the lines:
print(len(stopWords)) print(stopWords) |
We create a new list called wordsFiltered which contains all words which are not stop words.
To create it we iterate over the list of words and only add it if its not in the stopWords list.
for w in words: if w not in stopWords: wordsFiltered.append(w) |
NLTK – stemming
A word stem is part of a word. It is sort of a normalization idea, but linguistic.
For example, the stem of the word waiting is wait.
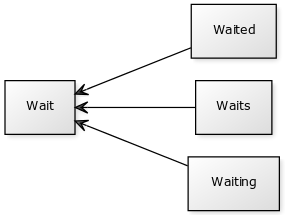
Given words, NLTK can find the stems.
Related courseNLTK – stemming
Start by defining some words:
words = ["game","gaming","gamed","games"] |
We import the module:
from nltk.stem import PorterStemmer from nltk.tokenize import sent_tokenize, word_tokenize |
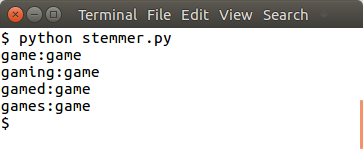
And stem the words in the list using:
from nltk.stem import PorterStemmer from nltk.tokenize import sent_tokenize, word_tokenize words = ["game","gaming","gamed","games"] ps = PorterStemmer() for word in words: print(ps.stem(word)) |
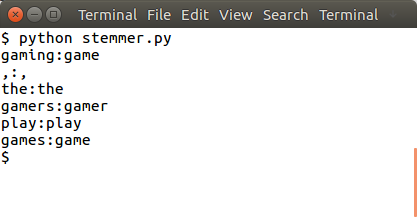
You can do word stemming for sentences too:
from nltk.stem import PorterStemmer from nltk.tokenize import sent_tokenize, word_tokenize ps = PorterStemmer() sentence = "gaming, the gamers play games" words = word_tokenize(sentence) for word in words: print(word + ":" + ps.stem(word)) |
There are more stemming algorithms, but Porter (PorterStemer) is the most popular.
NLTK speech tagging
The module NLTK can automatically tag speech.
Given a sentence or paragraph, it can label words such as verbs, nouns and so on.
NLTK – speech tagging example
The example below automatically tags words with a corresponding class.
import nltk from nltk.tokenize import PunktSentenceTokenizer document = 'Whether you\'re new to programming or an experienced developer, it\'s easy to learn and use Python.' sentences = nltk.sent_tokenize(document) for sent in sentences: print(nltk.pos_tag(nltk.word_tokenize(sent))) |
This will output a tuple for each word:

where the second element of the tuple is the class.
The meanings of these speech codes are shown in the table below:

We can filter this data based on the type of word:
import nltk from nltk.corpus import state_union from nltk.tokenize import PunktSentenceTokenizer document = 'Today the Netherlands celebrates King\'s Day. To honor this tradition, the Dutch embassy in San Francisco invited me to' sentences = nltk.sent_tokenize(document) data = [] for sent in sentences: data = data + nltk.pos_tag(nltk.word_tokenize(sent)) for word in data: if 'NNP' in word[1]: print(word) |
which outputs:
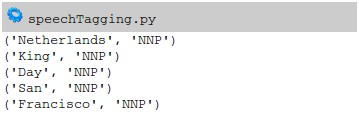
The classes include past tense, present. Using this technique we can quickly derive meaning from a text.
Natural Language Processing – prediction

Example: Given a product review, a computer can predict if its positive or negative based on the text.
In this article you will learn how to make a prediction program based on natural language processing.
nlp prediction example
Given a name, the classifier will predict if it’s a male or female.
To create our analysis program, we have several steps:
- Data preparation
- Feature extraction
- Training
- Prediction
Data preparation
The first step is to prepare data.
We use the names set included with nltk.
from nltk.corpus import names # Load data and training names = ([(name, 'male') for name in names.words('male.txt')] + [(name, 'female') for name in names.words('female.txt')]) |
This dataset is simply a collection of tuples. To give you an idea of what the dataset looks like:
[(u'Aaron', 'male'), (u'Abbey', 'male'), (u'Abbie', 'male')] [(u'Zorana', 'female'), (u'Zorina', 'female'), (u'Zorine', 'female')] |
You can define your own set of tuples if you wish, its simply a list containing many tuples.
Feature extraction
Based on the dataset, we prepare our feature. The feature we will use is the last letter of a name:
We define a featureset using:
featuresets = [(gender_features(n), g) for (n,g) in names] |
and the features (last letters) are extracted using:
def gender_features(word): return {'last_letter': word[-1]} |
Training and prediction
We train and predict using:
classifier = nltk.NaiveBayesClassifier.train(train_set) # Predict print(classifier.classify(gender_features('Frank'))) |
Example
A classifier has a training and a test phrase.
import nltk.classify.util from nltk.classify import NaiveBayesClassifier from nltk.corpus import names def gender_features(word): return {'last_letter': word[-1]} # Load data and training names = ([(name, 'male') for name in names.words('male.txt')] + [(name, 'female') for name in names.words('female.txt')]) featuresets = [(gender_features(n), g) for (n,g) in names] train_set = featuresets classifier = nltk.NaiveBayesClassifier.train(train_set) # Predict print(classifier.classify(gender_features('Frank'))) |
If you want to give the name during runtime, change the last line to:
# Predict name = input("Name: ") print(classifier.classify(gender_features(name))) |
For Python 2, use raw_input.
Python Sentiment Analysis
Sentiment Analysis
In Natural Language Processing there is a concept known as Sentiment Analysis.
Given a movie review or a tweet, it can be automatically classified in categories.
These categories can be user defined (positive, negative) or whichever classes you want.
Sentiment Analysis Example
Classification is done using several steps: training and prediction.
The training phase needs to have training data, this is example data in which we define examples. The classifier will use the training data to make predictions.
We start by defining 3 classes: positive, negative and neutral.
Each of these is defined by a vocabulary:
positive_vocab = [ 'awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)' ] negative_vocab = [ 'bad', 'terrible','useless', 'hate', ':(' ] neutral_vocab = [ 'movie','the','sound','was','is','actors','did','know','words','not' ] |
Every word is converted into a feature using a simplified bag of words model:
def word_feats(words): return dict([(word, True) for word in words]) positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab] negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab] neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab] |
Our training set is then the sum of these three feature sets:
train_set = negative_features + positive_features + neutral_features |
We train the classifier:
classifier = NaiveBayesClassifier.train(train_set) |
And make predictions.
Code example
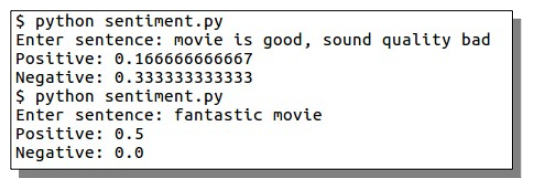
This example classifies sentences according to the training set.
import nltk.classify.util from nltk.classify import NaiveBayesClassifier from nltk.corpus import names def word_feats(words): return dict([(word, True) for word in words]) positive_vocab = [ 'awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)' ] negative_vocab = [ 'bad', 'terrible','useless', 'hate', ':(' ] neutral_vocab = [ 'movie','the','sound','was','is','actors','did','know','words','not' ] positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab] negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab] neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab] train_set = negative_features + positive_features + neutral_features classifier = NaiveBayesClassifier.train(train_set) # Predict neg = 0 pos = 0 sentence = "Awesome movie, I liked it" sentence = sentence.lower() words = sentence.split(' ') for word in words: classResult = classifier.classify( word_feats(word)) if classResult == 'neg': neg = neg + 1 if classResult == 'pos': pos = pos + 1 print('Positive: ' + str(float(pos)/len(words))) print('Negative: ' + str(float(neg)/len(words))) |
To enter the input sentence manually, use the input or raw_input functions.
The better your training data is, the more accurate your predictions. In this example our training data is very small.
Training sets
There are many training sets available:
A good dataset will increase the accuracy of your classifier.