
Category: pro
Python hosting: Host, run, and code Python in the cloud!
QT4 Messagebox
PyQT4 offers message box functionality using several functions.
Messageboxes included in PyQT4 are: question, warning, error, information, criticial and about box.
Related course:
PyQt4 mesagebox
The code below will display a message box with two buttons:
#! /usr/bin/env python # -*- coding: utf-8 -*- # import sys from PyQt4.QtGui import * # Create an PyQT4 application object. a = QApplication(sys.argv) # The QWidget widget is the base class of all user interface objects in PyQt4. w = QWidget() # Show a message box result = QMessageBox.question(w, 'Message', "Do you like Python?", QMessageBox.Yes | QMessageBox.No, QMessageBox.No) if result == QMessageBox.Yes: print 'Yes.' else: print 'No.' # Show window w.show() sys.exit(a.exec_()) |
Result:
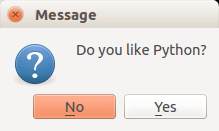
There are different types of messageboxes that PyQT4 provides.
PyQT4 Warning Box
You can display a warning box using this line of code:
QMessageBox.warning(w, "Message", "Are you sure you want to continue?") |
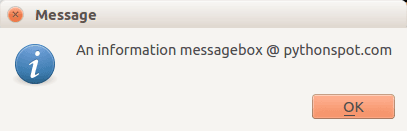
PyQT4 Information box
We can display an information box using QMessageBox.information()
QMessageBox.information(w, "Message", "An information messagebox @ pythonspot.com ") |
Result:
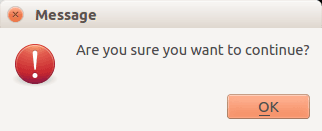
PyQT4 Critical Box
If something goes wrong in your application you may want to display an error message.
QMessageBox.critical(w, "Message", "No disk space left on device.") |
Result:
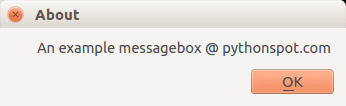
PyQT4 About box
We have shown the question box above.
QMessageBox.about(w, "About", "An example messagebox @ pythonspot.com ") |
Result:
Operaciones matemáticas
Puede utilizar el intérprete de Python como calculadora. Para ello simplemente iniciar Python sin un IDE y un nombre de archivo. Ejemplo:
Python 2.7.6 (por defecto, 22 de junio de 2015, 17:58:13) [GCC 4.8.2] de linux2 Tipo de "ayuda", "copyright", "créditos" o "licencia" para obtener más información. >>> 18 * 17 306 >>> 2 ** 4 16 >>>
Funciones matemáticas
Python soporta una amplia variedad de funciones matemáticas.
| Función | Devuelve | Ejemplo | |
|---|---|---|---|
| ABS(x) | Devuelve el valor absoluto de x. |
|
|
| CMP(x,y) |
Devuelve -1 Si x < y Devuelve 0 si x es igual a y Devuelve 1 Si x > y. |
|
|
| exp (x) | Devuelve la exponencial de x |
|
|
| Cienc | El logaritmo natural de x |
|
|
| log10(x) | El logaritmo en base 10 de x |
|
|
| Pow(x,y) | El resultado de x ** y |
|
|
| sqrt(x) | La raíz cuadrada de x |
|
IDEs de Python
Instalar un IDE de Python
Un Entorno de escritorio integrado (IDE) es un software para la programación. Además de edición de texto simple que tienen todo tipo de funciones tales como resaltado de sintaxis, completado de código, pestañas, un explorador de la clase y muchos más.
Python online intérpretes
Los intérpretes en línea no funcionen para todo pero funcionarán para la mayoría de los tutoriales para principiantes. Recomiendo usar un IDE desktop o el interprete oficial de Python.
Resumen de IDEs (sólo necesita uno)
| IDE | Autor | Plataforma | Descripción | Precio | Descargar |
|---|---|---|---|---|---|
| PyCharm | JetBrains | Windows, Mac OS X, Linux/UNIX | Python IDE. Características como: completación de código, inspecciones de código, error sobre la marcha destacando y soluciones rápidas | 89 € / 1er año. ($ 97,90) | Descarga PyCharm |
| Átomo (+ script plugin) | GitHub | Windows, Mac OS X, Linux/UNIX | Python IDE. Necesita descargar el plugin de secuencia de comandos después de instalar el átomo. | Gratis. | Descargar Atom. |
| Pythonista | OMZ:software | Apple iOS (iPhone, iPad) | Las características incluyen: resaltado de sintaxis, completado de código, sistema interactivo, módulos estándar y de iOS. | € 9. ($ 9,90) | Descargar Pythonista. |
| Eclipse con PyDev | Aleks Totic | Windows, Mac OS X, Linux/UNIX | Las características incluyen: sintaxis resaltado, refactorización de código, depuración gráfica y mucho más. | Gratis | Descargar |
| Eric Python IDE | Detlev Offenbach | Windows, Linux/UNIX | Las características incluyen: resaltado de sintaxis, autocompletado, clase navegador y más. | Gratis | Descargar |
| Wing IDE | Wingware | Windows, Mac OS X, Linux/UNIX | Características: Sintaxis resaltado, auto-completado, refactorización, pruebas unitarias y versión controlan. | $45 a $245 por usuario por licencia. | Descargar |
| Komodo IDE | Komodo | Windows, Mac OS X, Linux/UNIX | Características: Sintaxis, navegador de documentación, ejecutar código en línea, marcadores rápidos y mucho más. | € 40 a € 223. ($99 a $295). | Descargar |
| Skulpt | Skulpt | Web | Intérprete de Python | Gratis | Ejecutar en línea |
| Repl.it | Amjad Masad, Haya Odeh, Faris Masad y Max Shawabkeh. | Web | Intérprete de Python | Gratis | Ejecutar en línea |
| Ideone | Ideone | Web | Intérprete de Python | Gratis | Ejecutar en línea |
| CodePad | Hazel de Steven | Web | Intérprete de Python | Gratis | Ejecutar en línea |
SL4A: Android Python Scripting
Python scripts can be run on Android using the Scripting Layer For Android (SL4A) in combination with a Python interpreter for Android.
Related courses:
You may like:
SL4A
The SL4A project makes scripting on Android possible, it supports many programming languages including Python, Perl, Lua, BeanShell, JavaScript, JRuby and shell. The SL4A project has a lot of contributors from Google but it is not an official Google project.
Scripts can access Android specific features such as calling, text message (SMS), take picture, text to speech, bluetooth and many more.
In this article you will learn how to run Python on Android devices using SL4A.
SL4A is designed for developers
Keep in mind that SL4A is designed for developers and in alpha quality software.
Install SL4A

First enable installation of programs from unknown sources. By default Android devices can only install apps from the Google Play Store.
You have to enable the permission ‘Install from Unknown Sources’, by going to Settings -> Security -> Unknown Sources and tap the box.
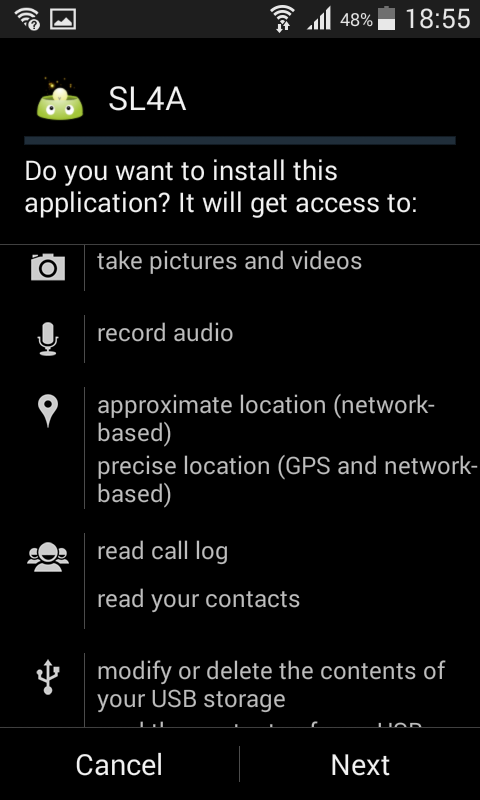
After you have have updated these settings donwload the SL4A APK. Visit https://github.com/kuri65536/sl4a on your Android device and download the SL4A APK (or use the QR code on the right).
Once downloaded an installation menu will popup, requesting all permissions on your Android device.
Install Python 3 for Android

Install the Py4A app. The Python for Android app is built to run solely on
Android devices. You should use this app together with SL4A.
You can pick any version of Py4A, but bare in mind the supported version on Android:
- Python 2 requires Android Device >= 1.6
- Python 3 requires Android Device >= 2.3.1
The git repository is: https://github.com/kuri65536/python-for-android/releases
You could also use the QR code on the right using a QR scanner on your Android device.
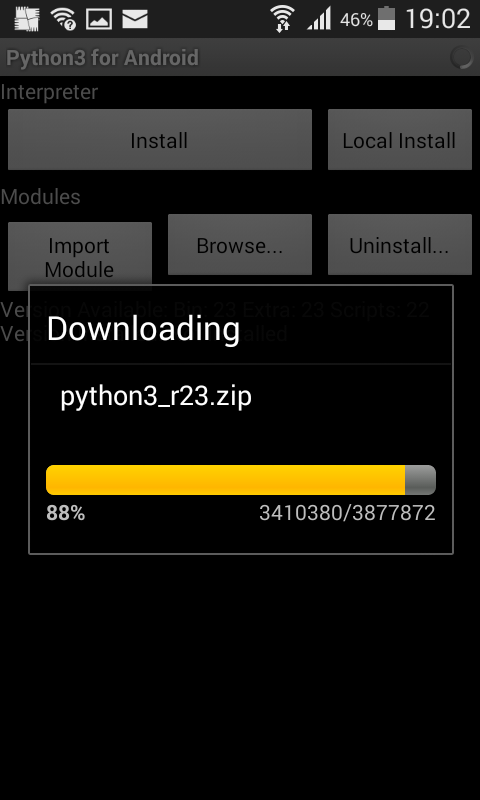
Once Py4A is installed, start the app and press install. This will install the Python interpreter.
SL4A
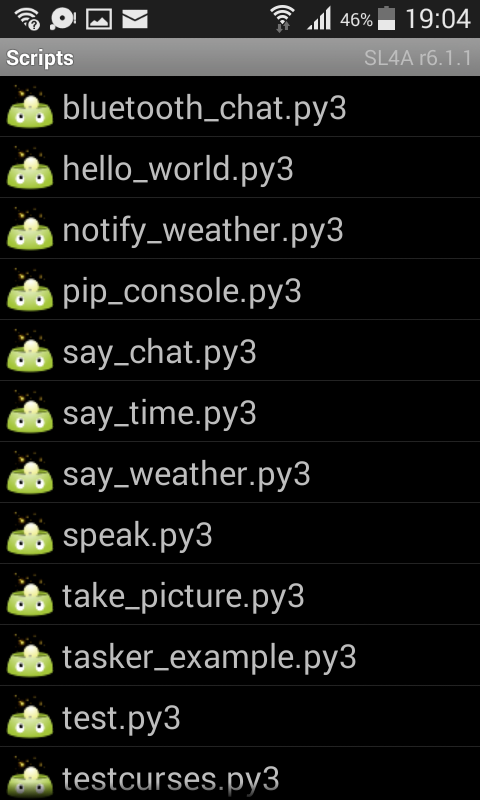
Open SL4A again. Many scripts will appear (in a list). You can now run Python scripts on your Android Device!
Press on a program such as speak.py A little popup will be shown. Pressing on the terminal icon will start the Python script.
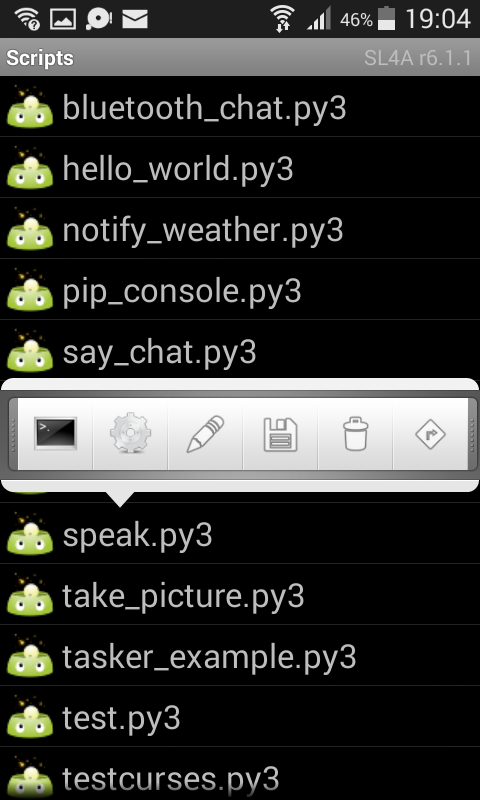
The third button (the pencil) will open an editor. This is not a full blown IDE but a simple editor.
It doesn’t have syntax highlighting.
Scripting on Android
You may prefer your favorite Python editor whatever it may be (vim/emacs fans here? PyCharm? Atom?)
All scripts are stored in /sl4a/scripts/
Note: File extension
If you installed the Python 3 interpreter, the programs will show with a .py3 extension instead of a .py extension.
A simple program (Spaceship Launch):
"""TTS Rocket Launch.""" __author__ = 'Frank <[email protected]>' import android droid = android.Android() message = "Python on Android" droid.ttsSpeak(message) for i in range(10,0,-1): droid.ttsSpeak(str(i)) droid.ttsSpeak("We have lift off!") droid.ttsSpeak("rrrrrr") |
More examples:
http://www.mattcutts.com/blog/android-barcode-scanner/
https://github.com/damonkohler/sl4a/blob/wiki/Tutorials.md
Extract links from webpage (BeautifulSoup)
Web scraping is the technique to extract data from a website.
The module BeautifulSoup is designed for web scraping. The BeautifulSoup module can handle HTML and XML. It provides simple method for searching, navigating and modifying the parse tree.
Related courses:
Get links from website
The example below prints all links on a webpage:
from BeautifulSoup import BeautifulSoup import urllib2 import re html_page = urllib2.urlopen("http://arstechnica.com") soup = BeautifulSoup(html_page) for link in soup.findAll('a', attrs={'href': re.compile("^http://")}): print link.get('href') |
It downloads the raw html code with the line:
html_page = urllib2.urlopen("http://arstechnica.com") |
A BeautifulSoup object is created and we use this object to find all links:
soup = BeautifulSoup(html_page) for link in soup.findAll('a', attrs={'href': re.compile("^http://")}): print link.get('href') |
Extract links from website into array
To store the links in an array you can use:
from BeautifulSoup import BeautifulSoup import urllib2 import re html_page = urllib2.urlopen("http://arstechnica.com") soup = BeautifulSoup(html_page) links = [] for link in soup.findAll('a', attrs={'href': re.compile("^http://")}): links.append(link.get('href')) print(links) |
Function to extract links from webpage
If you repeatingly extract links you can use the function below:
from BeautifulSoup import BeautifulSoup import urllib2 import re def getLinks(url): html_page = urllib2.urlopen(url) soup = BeautifulSoup(html_page) links = [] for link in soup.findAll('a', attrs={'href': re.compile("^http://")}): links.append(link.get('href')) return links print( getLinks("http://arstechnica.com") ) |
HTTP – Parse HTML and XHTML
In this article you will learn how to parse the HTML (HyperText Mark-up Language) of a website. There are several Python libraries to achieve that. We will give a demonstration of a few popular ones.
Beautiful Soup – a python package for parsing HTML and XML
This library is very popular and can even work with malformed markup. To get the contents of a single div, you can use the code below:
from BeautifulSoup import BeautifulSoup import urllib2 # get the contents response = urllib2.urlopen('http://en.wikipedia.org/wiki/Python_(programming_language)') html = response.read() parsed_html = BeautifulSoup(html) print parsed_html.body.find('div', attrs={'class':'toc'}) |
This will output the HTML code of within the div called ‘toc’ (table of contents) of the wikipedia article. If you want only the raw text use:
print parsed_html.body.find('div', attrs={'class':'toc'}).text |
If you want to get the page title, you need to get it from the head section:
print parsed_html.head.find('title').text |
To grab all images URLs from a website, you can use this code:
from BeautifulSoup import BeautifulSoup import urllib2 url = 'http://www.arstechnica.com/' data = urllib2.urlopen(url).read() soup = BeautifulSoup(data) links = soup.findAll('img', src=True) for link in links: print(link["src"]) |
To grab all URLs from the webpage, use this:
from BeautifulSoup import BeautifulSoup import urllib2 url = 'http://www.arstechnica.com/' data = urllib2.urlopen(url).read() soup = BeautifulSoup(data) links = soup.findAll('a') for link in links: print(link["href"]) |
PyQuery – a jquery like library for Python
To extract data from the tags we can use PyQuery. It can grab the actual text contents and the html contents, depending on what you need. To grab a tag you use the call pq(‘tag’).
from pyquery import PyQuery import urllib2 response = urllib2.urlopen('http://en.wikipedia.org/wiki/Python_(programming_language)') html = response.read() pq = PyQuery(html) tag = pq('div#toc') # print the text of the div print tag.text() # print the html of the div print tag.html() |
To get the title simply use:
tag = pq('title') |
HTMLParser – Simple HTML and XHTML parser
The usage of this library is very different. With this library you have to put all your logic in the WebParser class. A basic example of usage below:
from HTMLParser import HTMLParser import urllib2 # create parse class WebParser(HTMLParser): def handle_starttag(self, tag, attrs): print "Tag: " + tag # get the contents response = urllib2.urlopen('http://en.wikipedia.org/wiki/Python_(programming_language)') html = response.read() # instantiate the parser and fed it some HTML parser = WebParser() parser.feed(html) |